Decoupled Representation Learning for Skeleton-Based Gesture Recognition
Decoupled Representation Learning for Skeleton-Based Gesture Recognition
Abstract
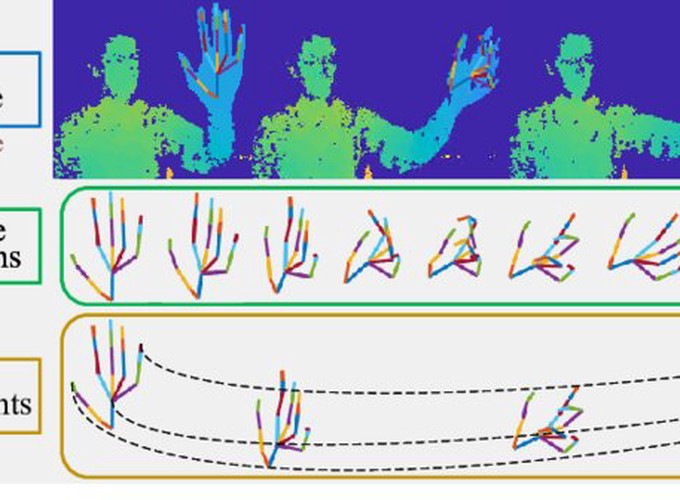
Skeleton-based gesture recognition is very challenging, as the high-level information in gesture is expressed by a sequence of complexly composite motions. Previous works of-ten learn all the motions with a single model. In this paper, we propose to decouple the gesture into hand posture variations and hand movements, which are then modeled separately. For the former, the skeleton sequence is embedded into a 3D hand posture evolution volume (HPEV) to represent fine-grained posture variations. For the latter, the shifts of hand center and fingertips are arranged as a 2D hand movement map (HMM) to capture holistic movements. To learn from the two inhomogeneous representations for gesture recognition, we propose an end-to-end two-stream net-work. The HPEV stream integrates both spatial layout and temporal evolution information of hand postures by a dedicated 3D CNN, while the HMM stream develops an efficient 2D CNN to extract hand movement features. Eventually, the predictions of the two streams are aggregated with high efficiency. Extensive experiments on SHREC’17 Track, DHG-14⁄28 and FPHA datasets demonstrate that our method is competitive with the state-of-the-art.