
Example results on MS-COCO and NUS-WIDE "with" and "without" knowledge distillation using our proposed framework. The texts on the right are the top-3 predictions, where correct ones are shown in blue and incorrect in red. The green bounding boxes in images are the top-10 proposals detected by the weakly-supervised detection model.
Abstract
Multi-label image classification (MLIC) is a fundamental but challenging task towards general visual understanding. Existing methods found the region-level cues (e.g., features from RoIs) can facilitate multi-label classification. Nevertheless, such methods usually require laborious object-level annotations (i.e., object labels and bounding boxes) for effective learning of the object-level visual features. In this paper, we propose a novel and efficient deep framework to boost multi-label classification by distilling knowledge from weakly-supervised detection task without bounding box annotations. Specifically, given the image-level annotations, (1) we first develop a weakly-supervised detection (WSD) model, and then (2) construct an end-to-end multi-label image classification framework augmented by a knowledge distillation module that guides the classification model by the WSD model according to the class-level predictions for the whole image and the object-level visual features for object RoIs. The WSD model is the teacher model and the classification model is the student model. After this cross-task knowledge distillation, the performance of the classification model is significantly improved and the efficiency is maintained since the WSD model can be safely discarded in the test phase. Extensive experiments on two large-scale datasets (MS-COCO and NUS-WIDE) show that our framework achieves superior performances over the state-of-the-art methods on both performance and efficiency.
Motivation
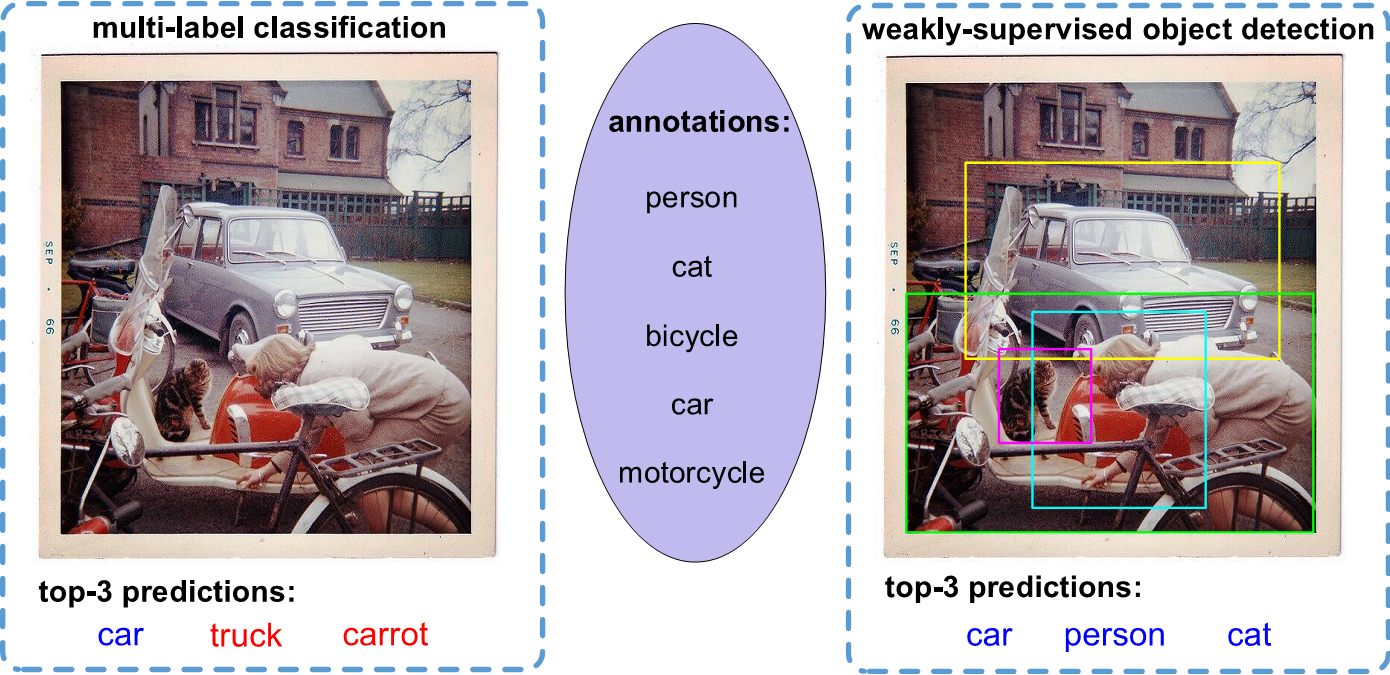
Correct predictions are shown in blue and incorrect in red.
-
The MLIC model might not predict well due to the lack of object-level feature extraction and localization for multiple semantic instances.
-
Although the results detected by WSD may not preserve object boundaries well, they tend to locate the semantic regions which are informative for classifying the target object, such that the predictions can still be improved.
-
Therefore, the localization results of WSD could provide object-relevant semantic regions while its image-level predictions could naturally capture the latent class dependencies. These unique advantages are very useful for the MLIC task.
Framework
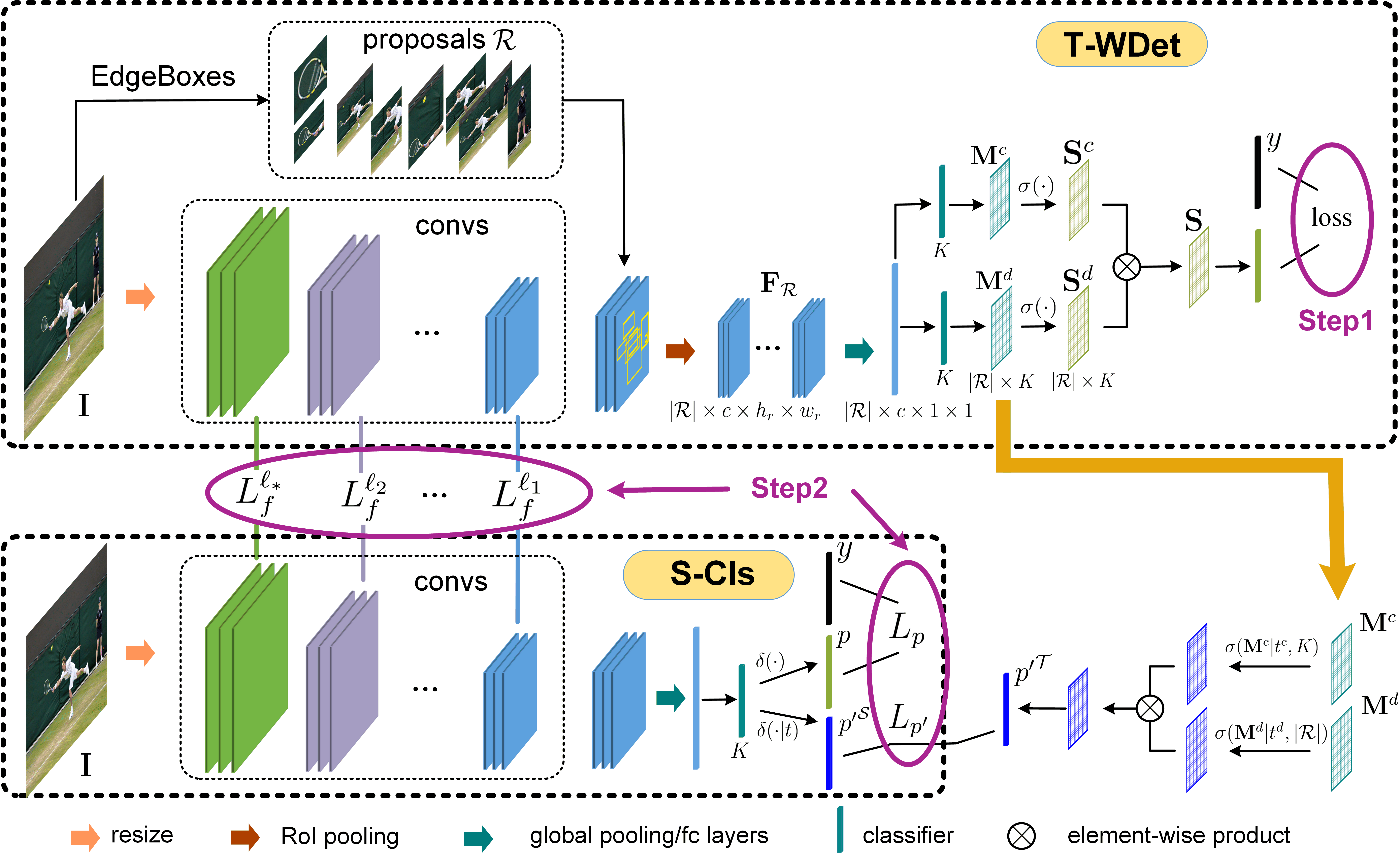
The proposed framework works with two steps: (1) we first develop a WSD model as teacher model (called T-WDet) with only image-level annotations y; (2) then the knowledge in T-WDet is distilled into the MLIC student model (called S-Cls) via feature-level distillation from RoIs and prediction-level distillation from the whole image, where the former is conducted by optimizing the loss in Eq. (3) while the latter is conducted by optimizing the losses in Eq. (5) and Eq. (10).
In this paper, we propose a novel and efficient deep framework to boost MLIC by distilling the unique knowledge from WSD into classification with only image-level annotations.
Specifically, our framework works with two steps:
- (1) we first develop a WSD model with image-level annotations;
-
(2) then we construct an end-to-end knowledge distillation framework by propagating the class-level holistic predictions and the object-level features from RoIs in the WSD model to the MLIC model, where the WSD model is taken as the teacher model (called T-WDet) and the classification model is the student model (called S-Cls).
-
The distillation of object-level features from RoIs focuses on perceiving localizations of semantic regions detected by the WSD model while the distillation of class-level holistic predictions aims at capturing class dependencies predicted by the WSD model.
- After this distillation, the classification model could be significantly improved and no longer need the WSD model, thus resulting in high efficiency in test phase. More details can be referred in the paper.
Ablation Study
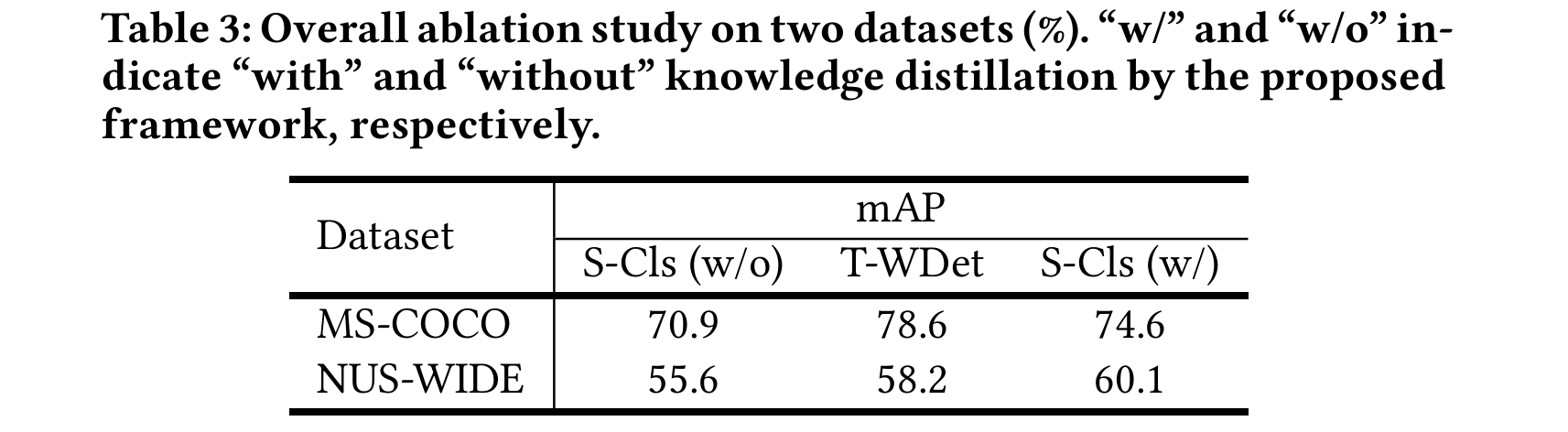
Overall Ablation
-
The T-WDet model achieves very good performance on MS-COCO while slightly better performance on NUS-WIDE. The reason may be that the clean object labels on MS-COCO are quite suitable for detection task while the noisy concept labels are not.
-
After distillation, the MLIC model not only has global information learned by itself, but also perceives the local semantic regions as complementary cues distilled from the WSD model, thus it could surpass the latter on NUS-WIDE.
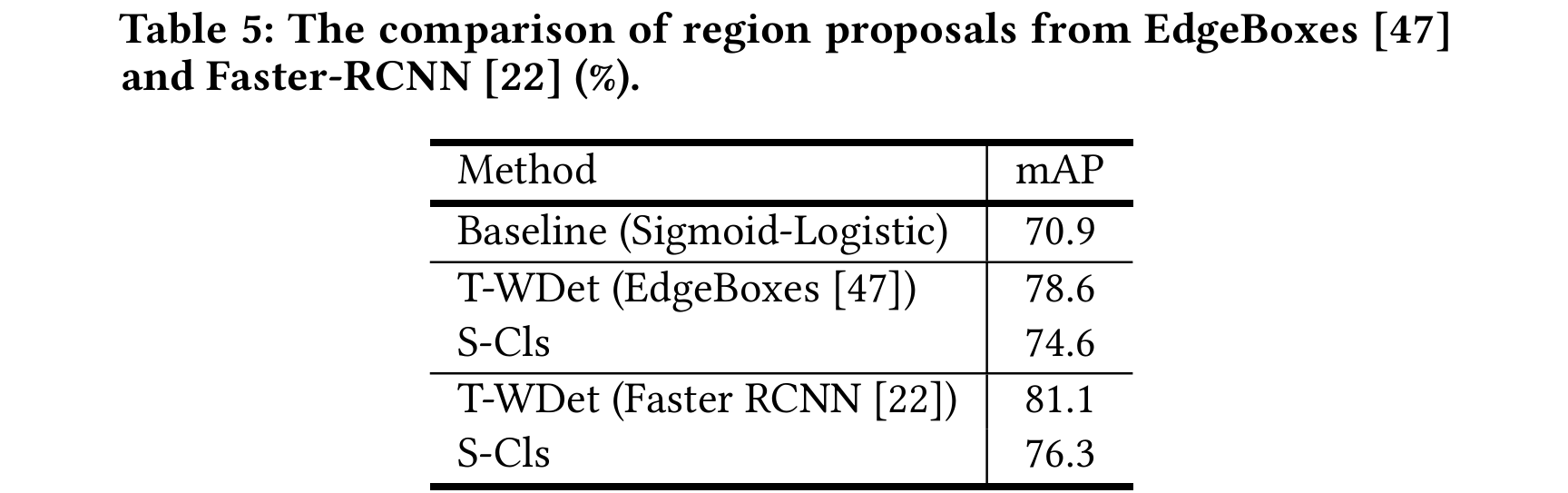
Region Proposal
-
The classification performance of T-WDet is improved from 78.6 to 81.1 when using the fully-supervised detection results (Faster-RCNN).
-
The S-Cls model is improved to 76.3 compared with EdgeBoxes proposals to 74.6, where the gap is not obvious. This further demonstrates the effectiveness and practicability of our proposed framework.
Robustness
The improvements of S-Cls model over each class/concept on MS-COCO (upper figure) and NUS-WIDE (lower figure) after knowledge distillation with our framework. "*k" indicates the number (divided by 1000) of images including this class/concept. The classes/concepts in horizontal axis are sorted by the number "*k" from large to small.
-
The improvements are also considerable even when the classes are very imbalanced (on NUS-WIDE, the classes in which the number of images is fewer are improved even more).
-
The improvements are robust to the object’s size and the label’s type. On MS-COCO, small objects like “bottle”, “fork”, “apple” and so on, which may be difficult for the classification model to pay attention, are also improved a lot. On NUS-WIDE, scenes (e.g., “rainbow”), events (e.g., “earthquake”) and objects (e.g., “book”) are all improved considerably.
Code
Please refer to the GitHub repository for more details.
Publication
Yongcheng Liu, Lu Sheng, Jing Shao, Junjie Yan, Shiming Xiang and Chunhong Pan, “Multi-Label Image Classification via Knowledge Distillation from Weakly-Supervised Detection”, in ACM International Conference on Multimedia (MM), 2018. [ACM DL] [arXiv]
@inproceedings{liu2018mlickdwsd,
author = {Yongcheng Liu and
Lu Sheng and
Jing Shao and
Junjie Yan and
Shiming Xiang and
Chunhong Pan},
title = {Multi-Label Image Classification via Knowledge Distillation from Weakly-Supervised Detection},
booktitle = {ACM International Conference on Multimedia},
pages = {700--708},
year = {2018}
}